Reasoning reimagined: Introducing Phi-4-mini-flash-reasoning

Experience quicker, more efficient reasoning with Phi-4-mini-flash-reasoning—designed specifically for edge, mobile, and real-time applications.
Revolutionary Architecture That Speeds Up Reasoning Models
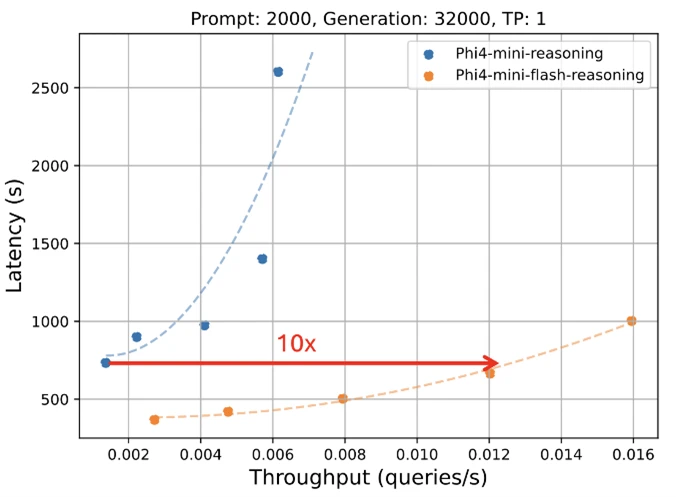
We’re thrilled to introduce the latest addition to the Phi model range: Phi-4-mini-flash-reasoning. Tailored for situations where computational power, memory, and latency are limited, this model is crafted to deliver top-tier reasoning capabilities to edge devices, mobile apps, and other resource-restrained settings. Following in the footsteps of Phi-4-mini, it adopts an innovative hybrid architecture that boosts throughput by up to 10 times and reduces latency by 2 to 3 times on average, ensuring much faster inference without losing reasoning quality. Phi-4-mini-flash-reasoning is now available on Azure AI Foundry, NVIDIA API Catalog, and Hugging Face.
Efficient Without Compromise
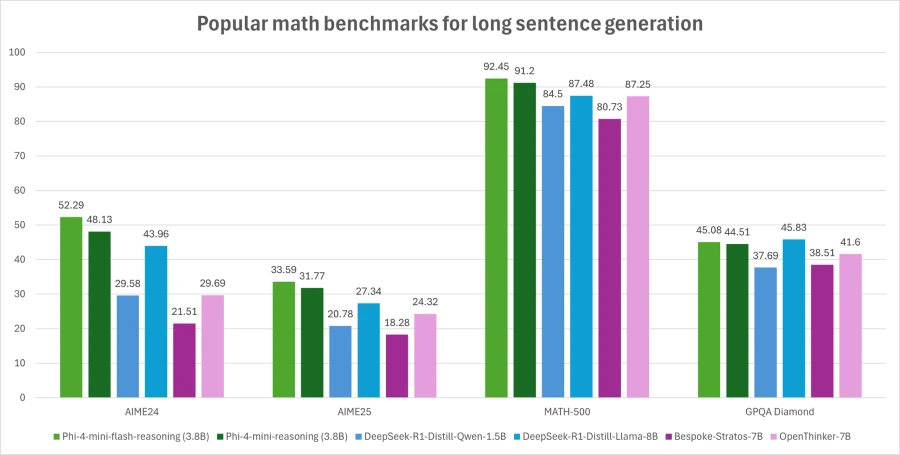
Phi-4-mini-flash-reasoning strikes a perfect balance between mathematical reasoning capabilities and efficiency, making it a fantastic choice for educational tools, real-time logic applications, and more.
Like its predecessor, this model stands at 3.8 billion parameters, optimised for improved mathematical reasoning. It supports a context length of 64K tokens and is fine-tuned with top-grade synthetic data, ensuring reliable, logic-driven performance in deployment.
What’s New?
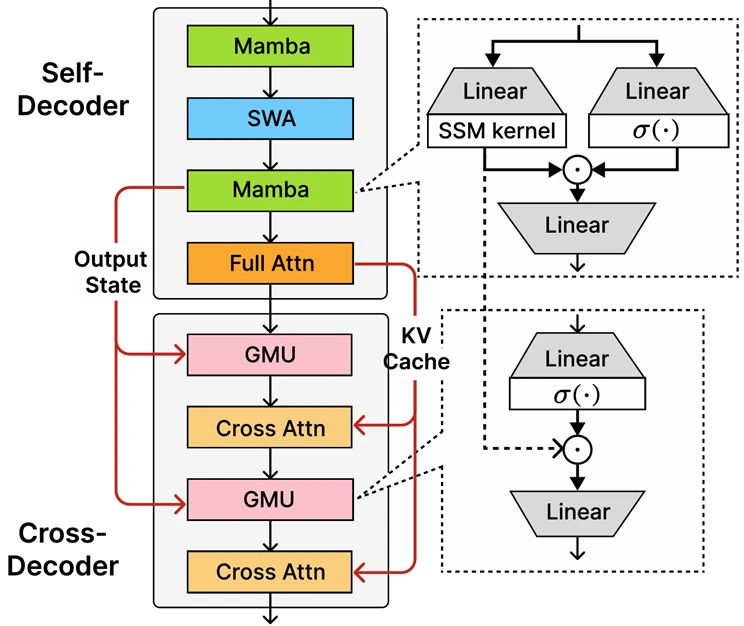
At the heart of Phi-4-mini-flash-reasoning lies the newly launched decoder-hybrid-decoder architecture called SambaY. Its standout feature is the Gated Memory Unit (GMU), a straightforward yet powerful mechanism that facilitates the sharing of representations between layers. The architecture incorporates a self-decoder that fuses Mamba (a State Space Model) with Sliding Window Attention (SWA), as well as a single layer of full attention. Additionally, it features a cross-decoder that intersperses costly cross-attention layers with the new, efficient GMUs. This innovative design significantly enhances decoding efficiency, improves long-context retrieval performance, and equips the architecture to excel across a variety of tasks.
Key advantages of the SambaY architecture include:
- Boosted decoding efficiency.
- Maintains linear pre-filling time complexity.
- Greater scalability and better long-context performance.
- Up to 10 times increased throughput.
Benchmarks of Phi-4-mini-flash-reasoning
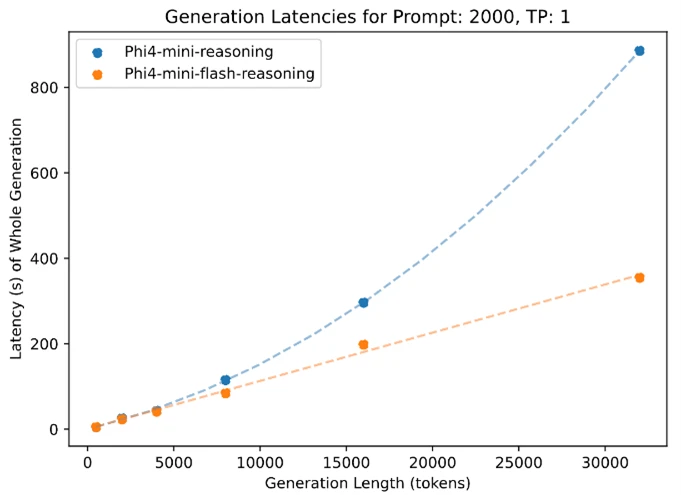
Like all models in the Phi lineup, Phi-4-mini-flash-reasoning is deployable on a single GPU, making it accessible for numerous applications. What sets it apart, however, is its architectural benefits. This model offers notably lower latency and higher throughput when compared to Phi-4-mini-reasoning, especially for long-context generation and latency-sensitive reasoning tasks.
This makes Phi-4-mini-flash-reasoning an appealing choice for developers and businesses aiming to implement intelligent systems that need quick, scalable, and efficient reasoning capabilities, whether on-site or on-device.
Potential Use Cases
With its lower latency and enhanced throughput focused on mathematical reasoning, this model is perfect for:
- Adaptive learning platforms that require timely feedback.
- On-device reasoning helpers, like mobile study tools or edge-based logic agents.
- Interactive tutoring systems that adjust content difficulty dynamically based on learner performance.
Its strengths in mathematical and structured reasoning make it exceptionally beneficial for educational technology, lightweight simulations, and automated assessment tools that demand swift logic inference with rapid response times.
Developers are invited to join the Microsoft Developer Discord community to ask questions, share insights, and explore real-world applications together.
Microsoft’s Pledge for Trustworthy AI
Various industries are harnessing Azure AI and Microsoft 365 Copilot capabilities to enhance growth, boost productivity, and create enriching user experiences.
We are dedicated to helping organisations utilise and develop trustworthy AI, ensuring it is secure, private, and reliable. Our extensive experience in AI development enables us to offer industry-leading guarantees that encompass our three core principles of security, privacy, and safety. Trustworthy AI emerges when we combine these commitments, such as our Secure Future Initiative and responsible AI principles, with our product capabilities, allowing a confident AI transformation.
The Phi model family, including Phi-4-mini-flash-reasoning, adheres to Microsoft AI principles: accountability, transparency, fairness, reliability, safety, privacy, security, and inclusivity.
We employ a thorough safety post-training framework that integrates Supervised Fine-Tuning (SFT), Direct Preference Optimisation (DPO), and Reinforcement Learning from Human Feedback (RLHF). These methods are realigned with both open-source and proprietary datasets to emphasise helpfulness, reduce harmful outputs, and tackle a wide spectrum of safety issues. We encourage developers to adopt responsible AI best practices tailored to their unique use cases and cultural nuances.
For more information on risks and mitigation strategies, please refer to the model card.
Discover More About This New Model
Start Creating with Azure AI Foundry
Share this content:


