Introducing Fireworks AI on Microsoft Foundry: Bringing high performance, low latency open model inference to Azure

We are thrilled to announce the public preview of Fireworks AI on Microsoft Foundry, introducing high-performance open model inference into Azure. This integration demonstrates Microsoft Foundry’s commitment to offering developers a comprehensive platform where they can efficiently run, customise, and operationalise open models as part of a complete, enterprise-ready AI lifecycle.
Across various sectors, many organisations are choosing to standardise on open models. This shift provides them with improved control over performance, cost, customisation, and the necessary security and compliance for enterprise deployments. Open models empower teams with the flexibility to select the right architecture for each task while avoiding dependency on a single model provider as their requirements adapt.
However, as adoption rates rise, relying solely on performance isn’t enough. Teams now seek a reliable method to assess models quickly, operate them securely in production, and enhance them over time without the need to reconstruct infrastructure or complicate their toolsets. Often, organisations find themselves piecing together custom serving stacks, which can impede innovation and make scaling challenging.
Microsoft Foundry aims to tackle this issue. It provides a cohesive system of record and enterprise control plane for AI, uniting models, agents, evaluation, deployment, and governance into one seamless experience. With Microsoft Foundry, teams can confidently transition from experimentation to production, utilising the models and frameworks that best meet their needs while relying on a consistent operational foundation.
We are excited to share that Fireworks AI is now in public preview on Microsoft Foundry, marking a milestone in delivering high-performance open model inference to Azure. This move aligns with Microsoft Foundry’s vision of being the one-stop solution for developers to efficiently run, adapt, and operationalise open models as part of a holistic AI strategy.
Fireworks AI Models on Microsoft Foundry: Your Central Hub for Open Models
Fireworks AI offers top-notch inference capabilities for open models, and Microsoft Foundry ensures this performance is accessible at an enterprise level. By engaging with Fireworks AI via Microsoft Foundry, teams gain a single, trusted control plane to evaluate, deploy, customise, and manage open models alongside their entire AI ecosystem.
As the world of open models progresses, customisation is no longer limited to just training. It has expanded to include consistent methods for configuring, deploying, optimising, governing, and iterating production models without the need to juggle multiple tools or systems. Microsoft Foundry creates a standardised environment for these workflows, while Fireworks AI delivers the efficiency and performance essential for running open models at scale. This allows teams to transition from trials to production, utilising open models seamlessly instead of cobbling together different tools and deployment strategies.
The combination of Fireworks AI and Microsoft Foundry provides a holistic and sustainable approach to managing open models, merging swift, effective inference with a platform crafted to support long-term enterprise model operations.
With Fireworks AI available on Foundry, developers can access superior inference for open models, including tailored deployments for custom weight models. Fireworks AI stands out as a leader in high-performance inference for open models. Its engine operates at internet scale, processing over 13 trillion tokens daily, handling roughly 180,000 requests per second, and achieving over 1,000 tokens per second on large models, as validated by leading benchmarks at Artificial Analysis. This exceptional performance is now accessible on Foundry.
Developers can log into Foundry today and gain access to these open models with Fireworks AI:
- DeepSeek V3.2
- OpenAI gpt-oss-120b
- Kimi K2.5
- MiniMax M2.5 (new)
This update introduces a new model, MiniMax M2.5, to Foundry with serverless support and enhanced inference options for already popular open models.
With Fireworks AI within Microsoft Foundry, developers can:
- Speed up model evaluation with immediate access and support: Get started quickly by leveraging cutting-edge open models from Fireworks AI through a single Azure endpoint via Foundry.
- Enhance inference: Requests to open models are handled by Fireworks’ high-throughput inference system, ensuring rapid performance paired with Azure-standard governance.
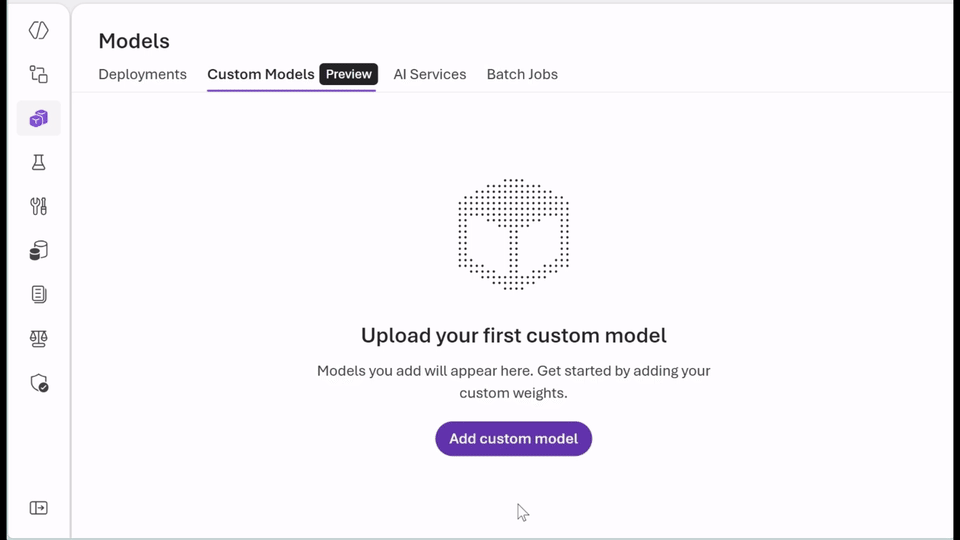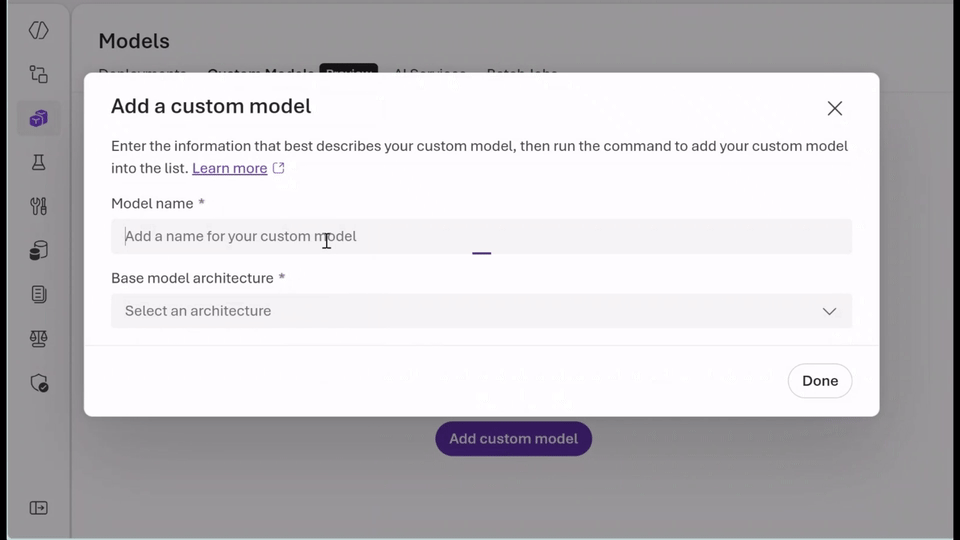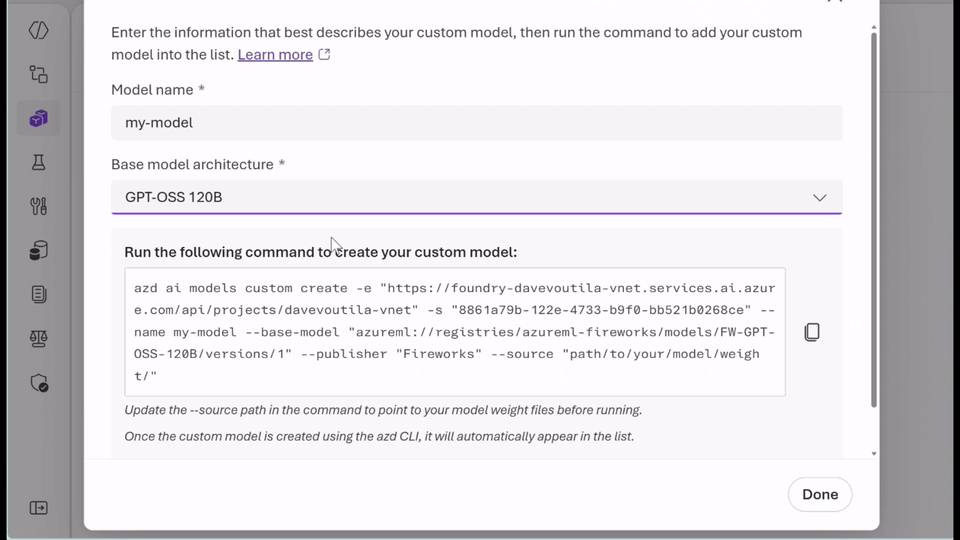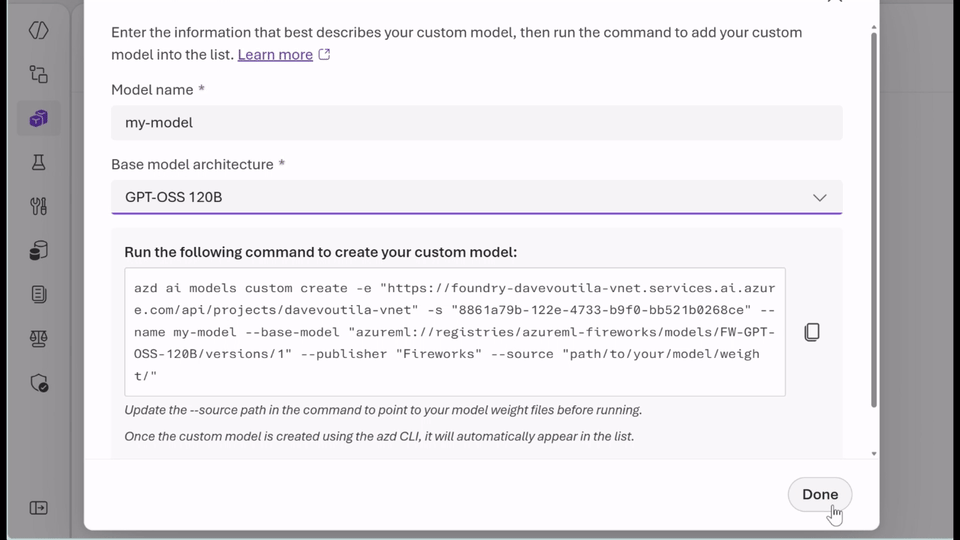
- Utilise familiar models: With the bring-your-own-weights (BYOW) feature, you can upload and register quantised or fine-tuned weights developed elsewhere without altering the serving infrastructure.
- Select the best pricing model for your tasks: Use serverless, pay-per-token inference for secure and rapid experimentation with Data Zone Standard, or opt for provisioned throughput units (PTUs) for predictable, steady performance with either base or custom models. This flexibility allows you to optimise for agility or efficiency without the burden of infrastructure management.
- Operate with enterprise confidence and scalability: We’re dedicated to helping customers rapidly build production-ready AI applications while ensuring the highest levels of safety and security. Foundry offers a comprehensive workspace for agent development, evaluation, and deployment, complete with unified governance, observability, and tools designed for agents.
The Future of Fireworks and AI Applications
Microsoft Foundry is continually evolving to cater to the entire lifecycle of open models—ranging from initial evaluations to operational deployment and ongoing optimisation. As teams expand their implementation of open models, having a reliable, enterprise-ready foundation becomes increasingly vital.
By merging Fireworks AI with Microsoft Foundry, developers unlock high-performance inference today while utilising a platform that supports further customisation and enterprise tasks over time. This strategy empowers teams to embrace open models not just for their current capabilities, but also for their potential to adapt and operate seamlessly as AI needs evolve. We look forward to seeing how developers and businesses leverage Fireworks AI on Microsoft Foundry to enhance the next wave of intelligent applications.
Getting Started:
- Visit Microsoft Foundry and explore the Fireworks AI open models in the model catalog.
- Choose the open model hosted by Fireworks.
- Examine the model card.
- Select your preferred deployment option—serverless or PTU—and proceed with the deployment.
Discover More About Fireworks on Microsoft Foundry
Share this content:


